The Spring framework provides the @Repository annotation and the Repository interface.
Although related and a bit confusing initially, they perform distinct tasks.
The Java annotation is meta-data and therefore does not provide any specific behaviors. However, using it tells Spring that the class can be automatically discovered when auto-configuration is enabled, the class will also be treated like a standard Spring component which is helpful if you want consistent error handling.
The interface on the other hand defines common tasks performed with data sources, e.g., Create, Read, Update, and Delete.
Spring Data Access and Spring Data Commons
The @Repository annotation is part of the Data Access
module, included in the Spring Framework, whereas the Repository interface is
part of Spring Data Commons. These are their fully qualified names:
org.springframework.stereotype.Repository
org.springframework.data.repository.RepositoryRepository as a stereotype: Data Access
The @Repository annotation is a Spring stereotype, a stereotype represents the
architectural role an application component would typically play. It is commonly
used in two non-interchangeable ways; one refers to a Repository, in the sense described
in Domain Driven Design:
… a mechanism for encapsulating storage, retrieval, and search behavior which emulates a collection of objects.
the annotation is also used is to implement a traditional Java EE pattern, a Data Access Object:
Use a Data Access Object (DAO) to abstract and encapsulate all access to the data source. The DAO manages the connection with the data source to obtain and store data.
The annotation is agnostic of the semantics, and therefore it general-purpose. However,
annotating a class will give that class the ability to hook into Spring’s standardized
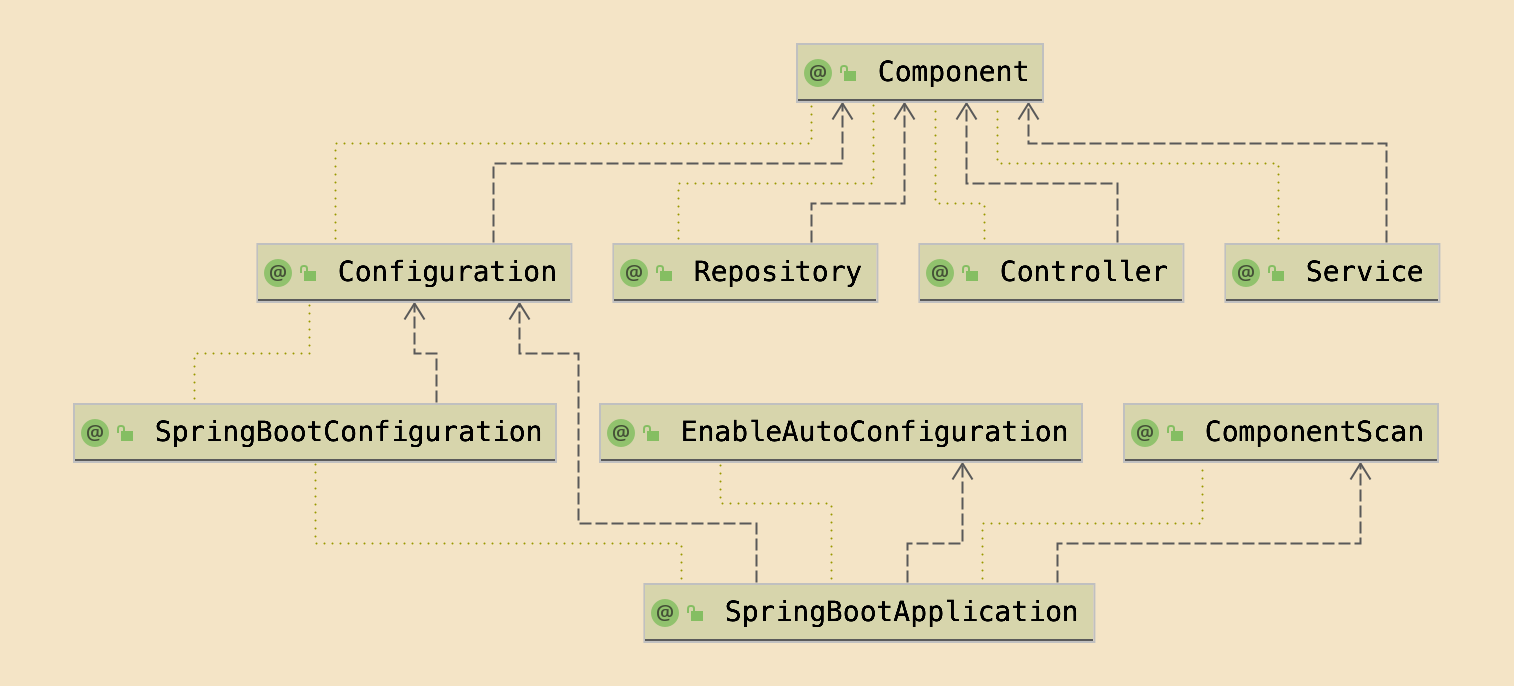
exception handling. In later versions of Spring, it also becomes a Spring @Component
and therefore is eligible for auto-discovery when auto-configuration is enabled in a
Spring Boot Application.
A repository with batteries included: Data Commons
The Spring Data Commons provides some supporting implementations for
common use cases involving repositories, the following diagram shows one such
implementation, SimpleJpaRepository.
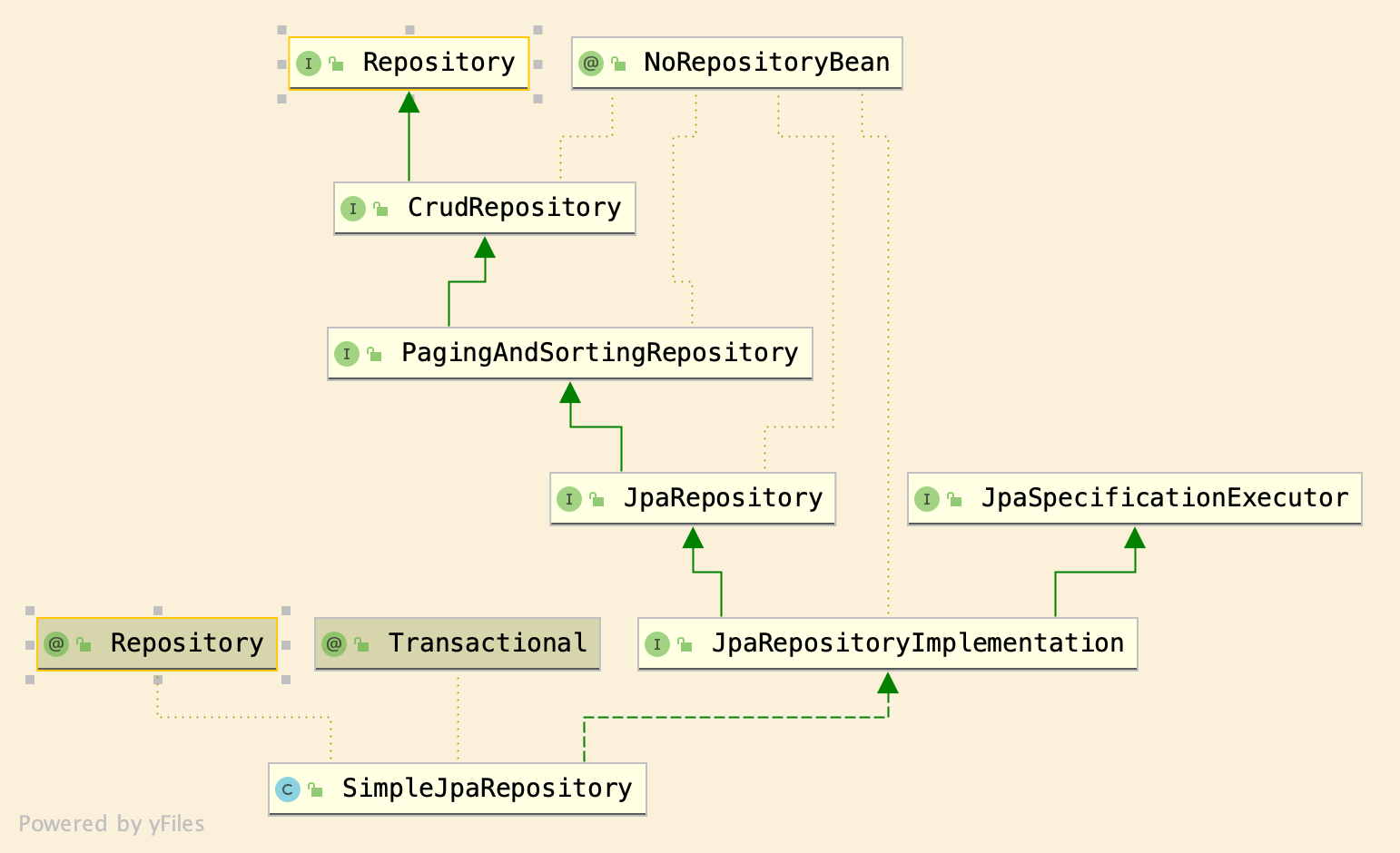
It’s worth noting that
SimpleJpaRepository
is annotated (dotted line) with @Repository and also
implements (dashed arrow) – although not directly – the Repository interface:
@Repository
public class SimpleJpaRepository implements JpaRepositoryImplementation {
...
}Here’s a break down of the features that come with it:
- support for CRUD operations because it extends (solid arrow) the
CrudRepositoryinterface - paging & sorting via extending the
PagingAndSortingRepositoryinterface - transaction management, provided by the
@Transactionalannotation - support for the JPA Criteria API by extending the
JpaSpecificationExecutorinterface
Spring’s auto-configuration will load all repositories, unless …
Since @Repository is also a @Component, every annotated class will be automatically
discovered and Spring will create and load an instance into the Application Context.
The @NoRepositoryBean annotation is used to stop Spring from automatically creating
those instances, typically done to avoid loading unwanted beans
to the Application Context.
How can a repository help?
If you can leverage the features provided by supporting implementations in the Data Commons repositories, then it’s a big productivity boost since you don’t have to write and maintain all that code.
If you have to write custom data access logic, by using the @Repository annotation you
will benefit from consistent exception handling and automatic loading of your
DAO components.
Either way, you benefit from the infrastructure provided by the framework and therefore can spend more time thinking about your domain and less about implementation details.
References
Stereotype (Spring Data Access)
Interface (Spring Data)
Google search terms
repository stereotype site:docs.spring.iorepository interface site:docs.spring.io
